
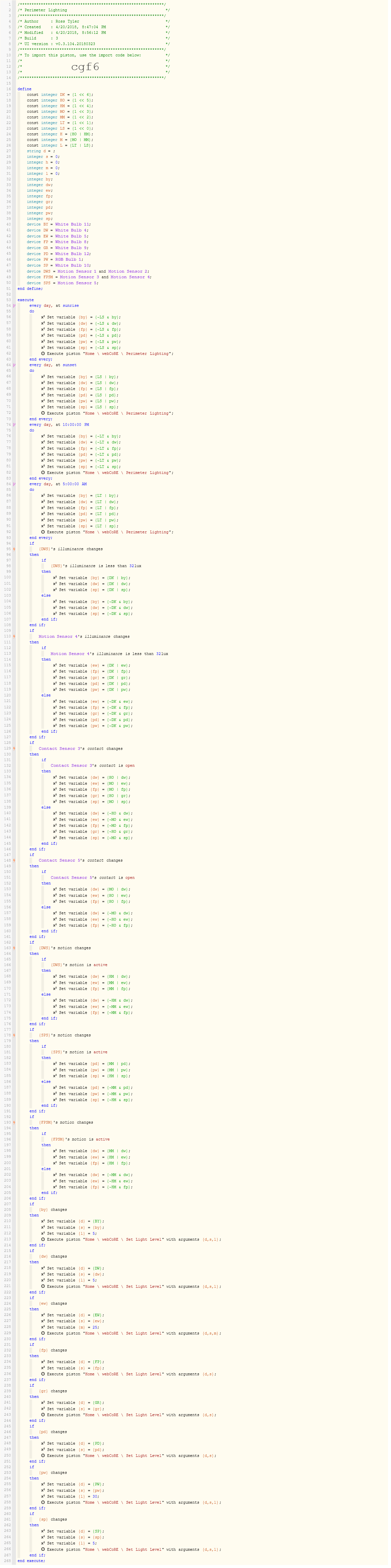
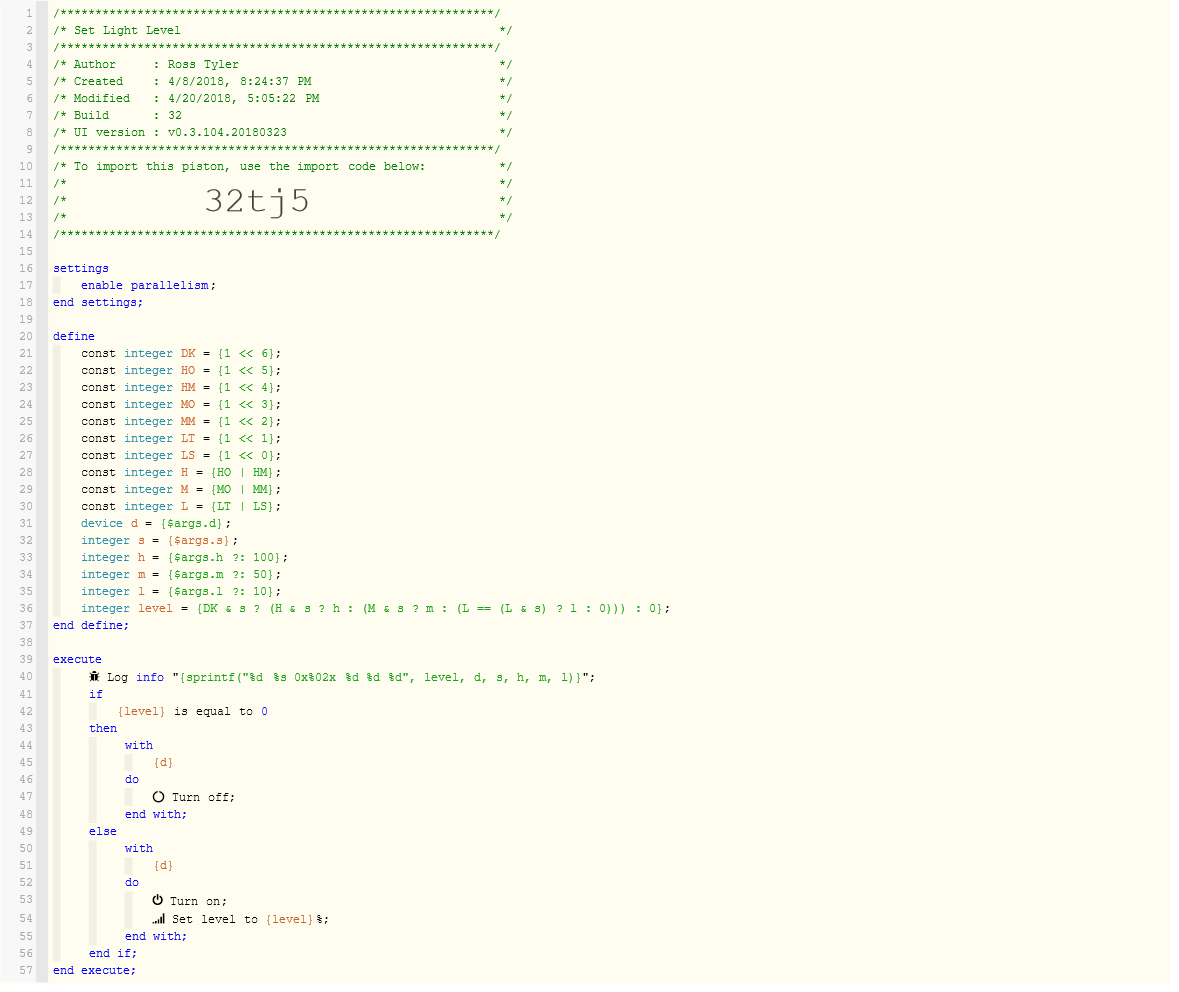
OK, but first an apology: Sorry, but because I have found success in doing so, the code is trimmed of comments and variable names are very short. Here is how it works …
My “Perimeter Lighting” piston is in charge of the state of all my perimeter lights based on the state of all my perimeter sensors. As sensor state changes, related lights are affected. The effect desired is that nearby (with regard to the sensors) lights are brightest, and the next nearest are not so bright. This results in the lights following sensed events around the perimeter and anticipating the next move. Some of the lights are also used as dim “landscape lighting” and, so, are also affected by time of day events and sunrise/sunset. All lights are affected by “darkness” as measured by nearby illumination sensors so that lights are not turned on unless it is dark.
Each light (e.g. DW for driveway) has a set of bit flags (e.g. dw) where each bit is controlled independently by sensor(s). The bits are for darkness (DK), requests for high brightness (H, from motion (HM) or open (HO) events), medium brightness (M, from motion (MM) or open (MO) events) or low brightness (L, from time (LT) and sun-based (LS) events).
The first part of “Perimeter Lighting” handles the sensed events. As they occur, the bits of state variables are flipped for their related lights. The last part checks to see if these state variables have changed and, if they have, they set the brightness of the light based on the latest state.
My “Set Light Level” piston, is given the light device, its state and, optionally, overriding high, medium and low levels for this light. The light will always be turned off unless it is dark (DK). Otherwise, if anyone wants it to be high (H), it will be set on at the high level (h). Otherwise, if anyone wants it to be medium (M), it will be set on at the medium level (m). Otherwise, if everyone wants it to be low (L), it will be set on at the low level (l). Otherwise, it will be turned off.
 in a closet…
in a closet… ). Borrowing your metaphor, it seems my team starts playing in a gym (54% memory used) and some time later find themselves in that closet (76% memory used). I thought I reserved the gym.
). Borrowing your metaphor, it seems my team starts playing in a gym (54% memory used) and some time later find themselves in that closet (76% memory used). I thought I reserved the gym.