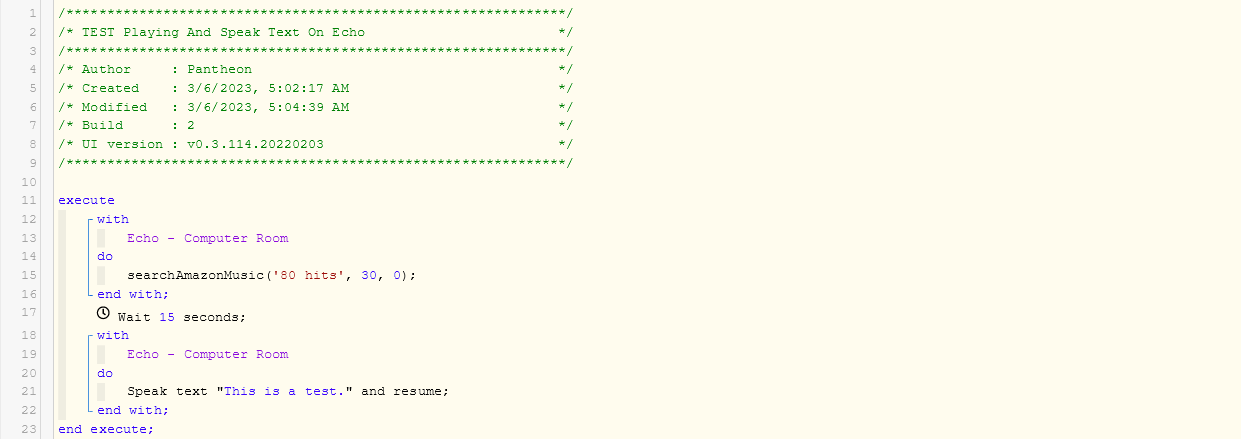
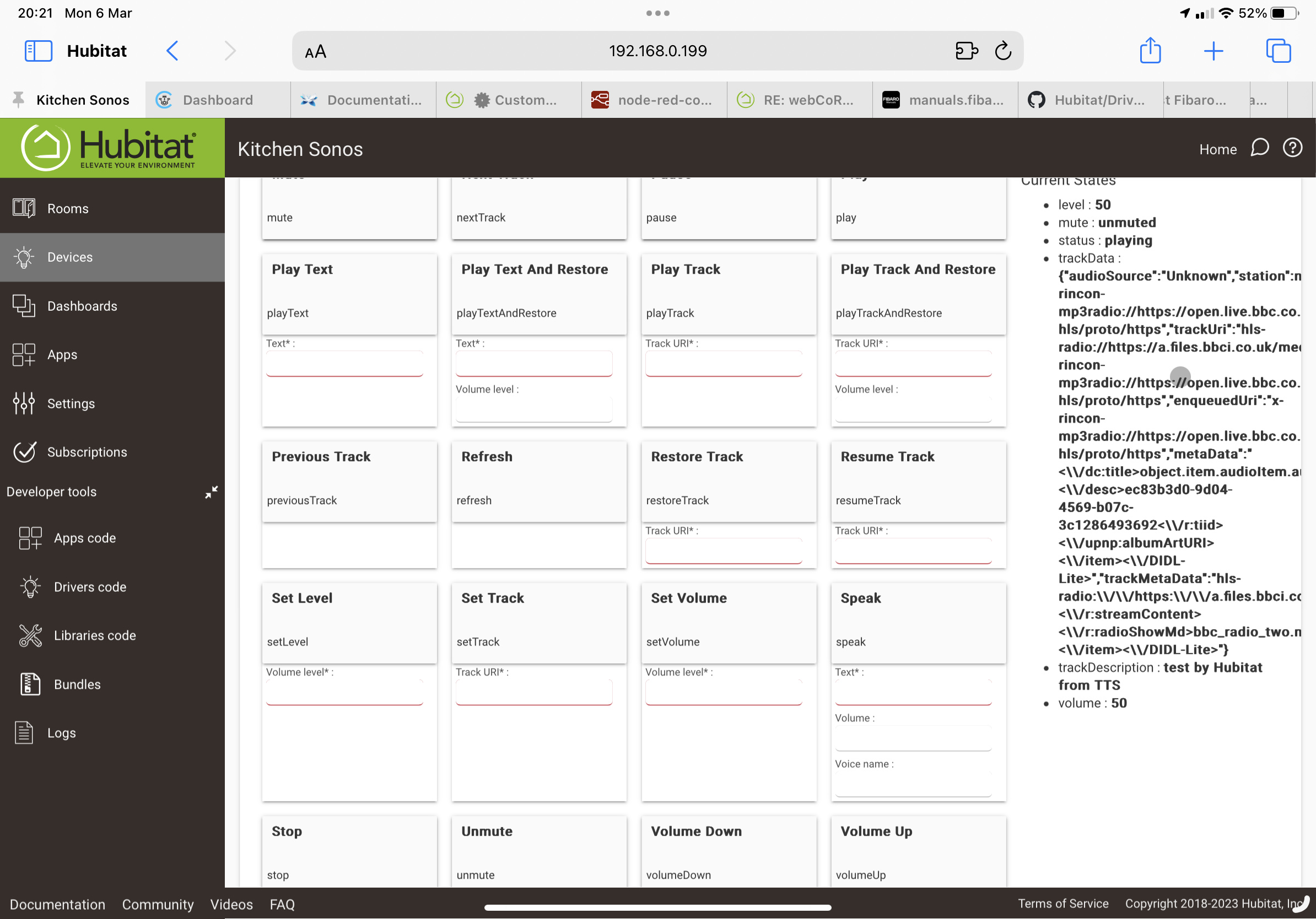
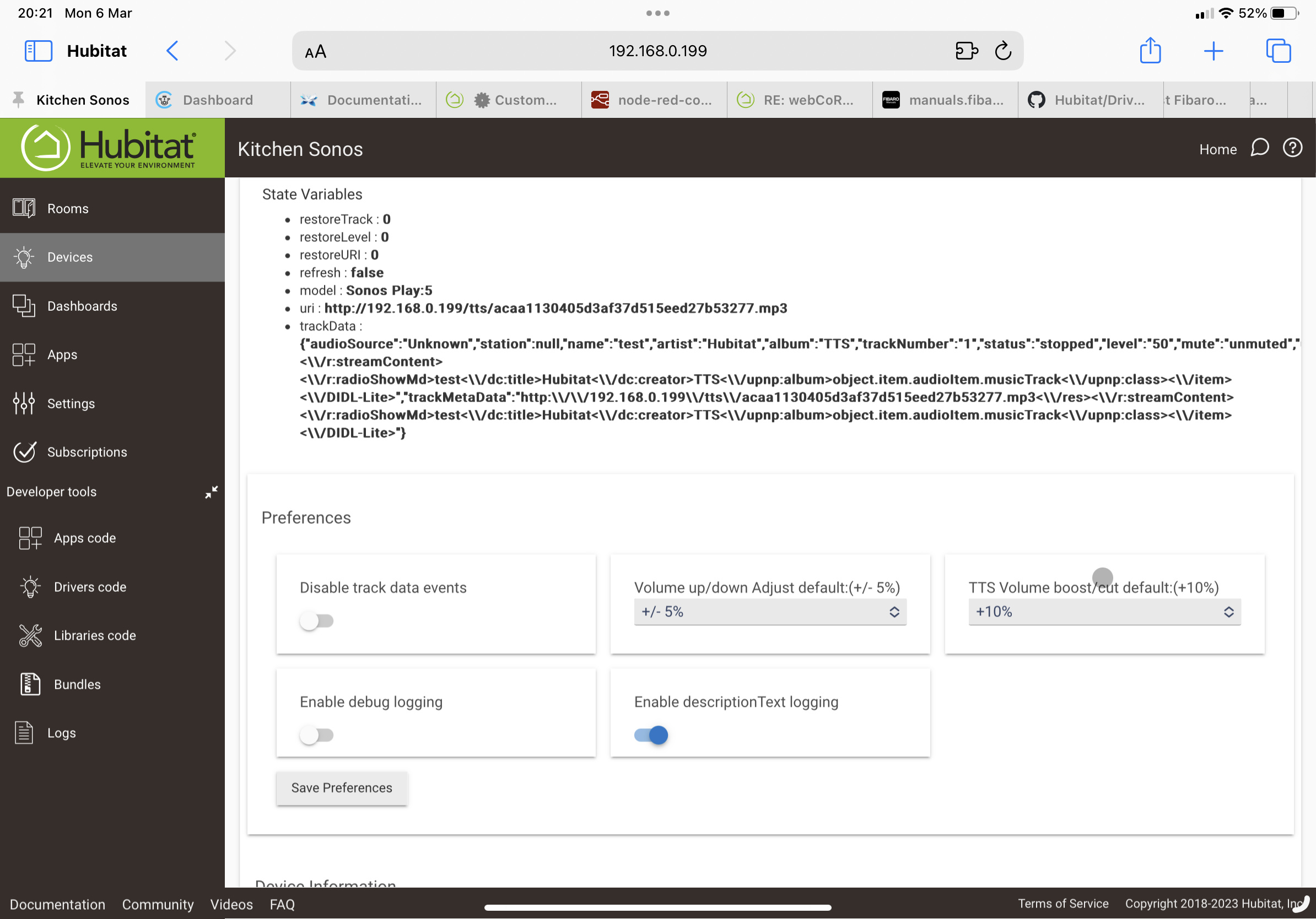
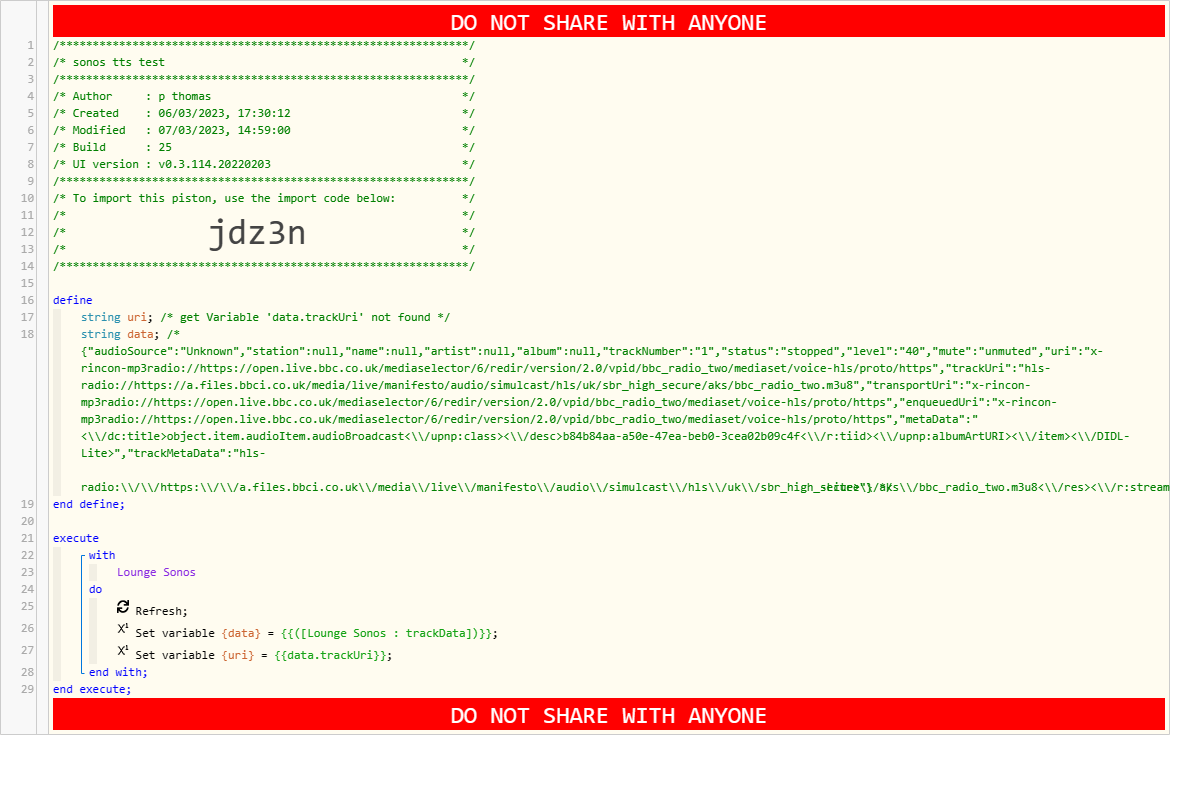
I use the above to make announcements, but find if something is already playing on the sonos, it does not resume after the text is spoken. This was the case on ST and also after migrating to HE.
Am I doing something wrong, or does this functionality not work?