1) Give a description of the problem
Sonos speaker is supposed to speak text and then resume playing with all attributes. Instead no text is spoken and music stops completely until I restart in another way. Speaker is otherwise responsive and is online.
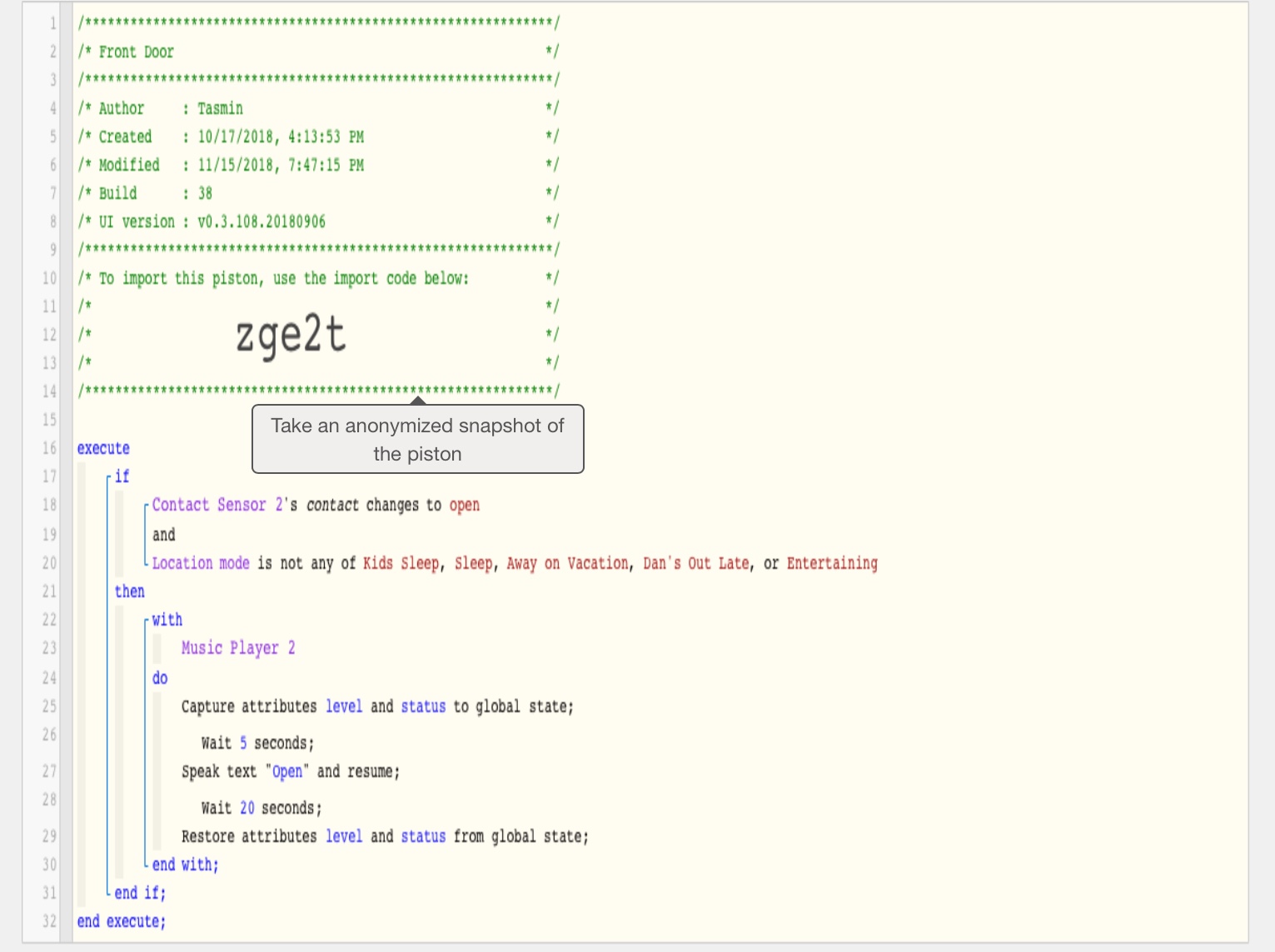
**4) Post a Green Snapshot of the piston
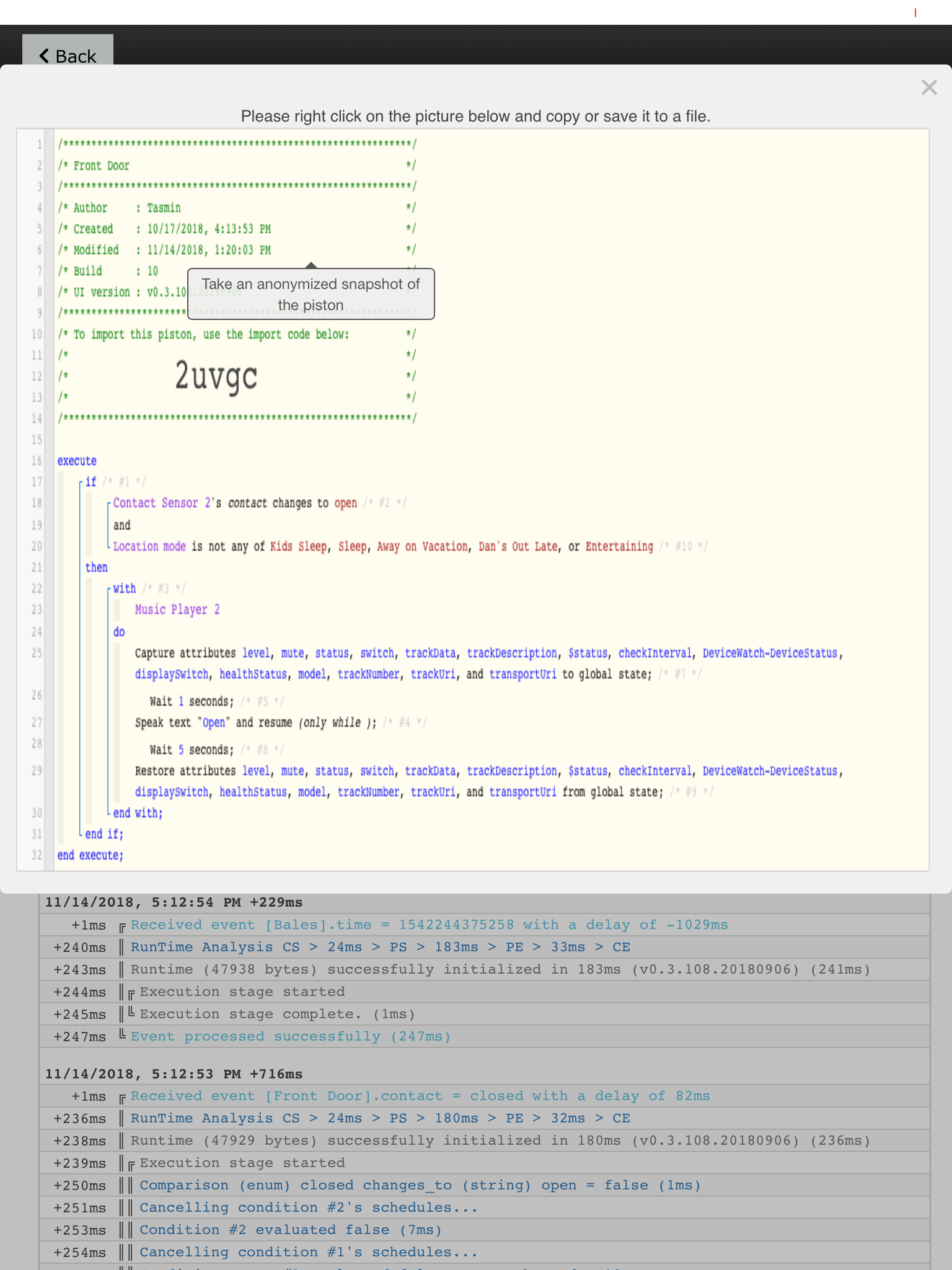
5) Attach any logs (From ST IDE and by turning logging level to Full)
(
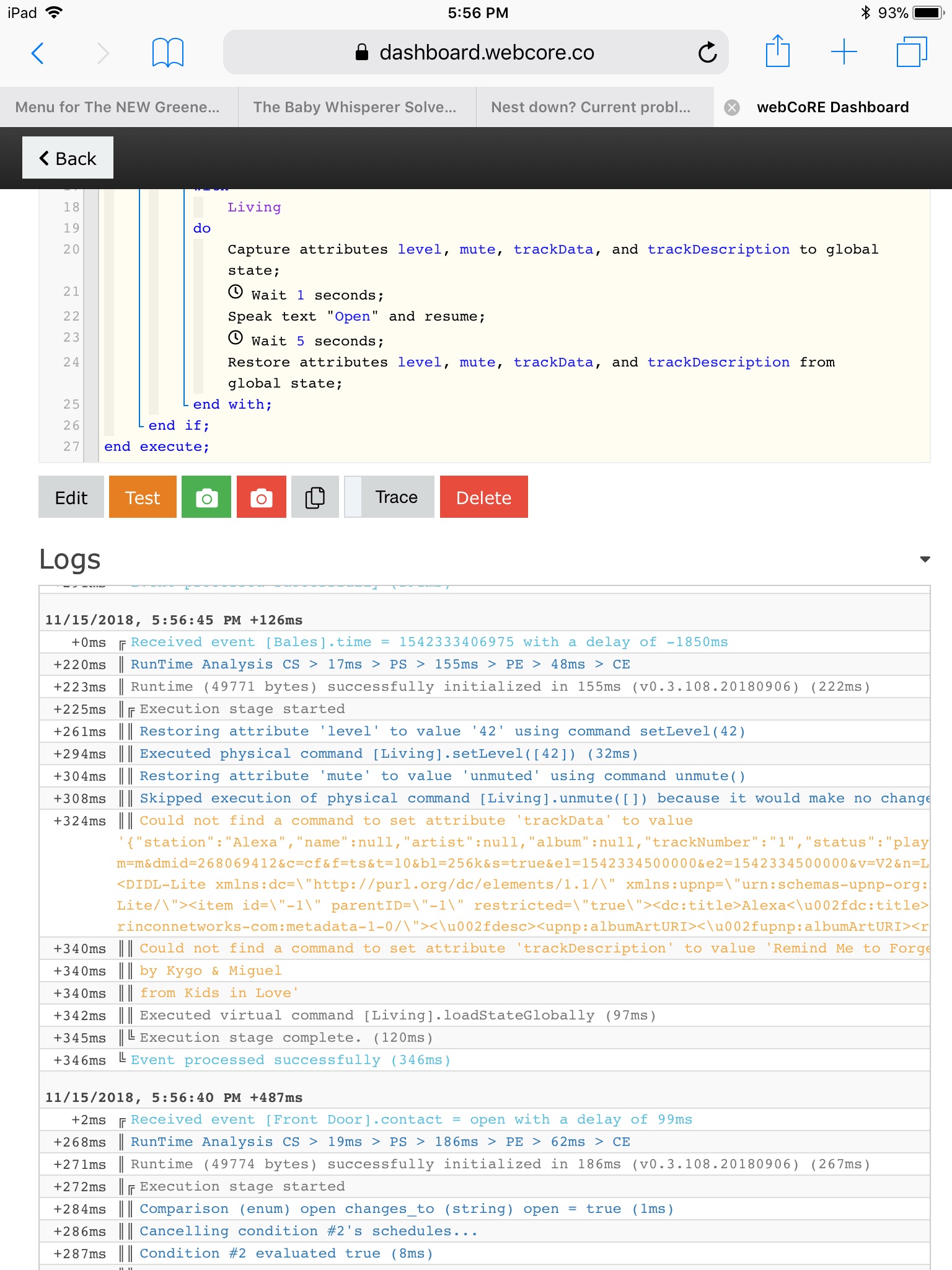
PS > 183ms > PE > 33ms > CE
+243ms ║Runtime (47938 bytes) successfully initialized in 183ms (v0.3.108.20180906) (241ms)
+244ms ║╔Execution stage started
+245ms ║╚Execution stage complete. (1ms)
+247ms ╚Event processed successfully (247ms)
11/14/2018, 5:12:53 PM +716ms
+1ms ╔Received event [Front Door].contact = closed with a delay of 82ms
+236ms ║RunTime Analysis CS > 24ms > PS > 180ms > PE > 32ms > CE
+238ms ║Runtime (47929 bytes) successfully initialized in 180ms (v0.3.108.20180906) (236ms)
+239ms ║╔Execution stage started
+250ms ║║Comparison (enum) closed changes_to (string) open = false (1ms)
+251ms ║║Cancelling condition #2’s schedules…
+253ms ║║Condition #2 evaluated false (7ms)
+254ms ║║Cancelling condition #1’s schedules…
+255ms ║║Condition group #1 evaluated false (state changed) (10ms)
+258ms ║╚Execution stage complete. (19ms)
+259ms ╚Event processed successfully (259ms)
11/14/2018, 5:12:48 PM +62ms
+2ms ╔Received event [Front Door].contact = open with a delay of 95ms
+350ms ║RunTime Analysis CS > 39ms > PS > 249ms > PE > 61ms > CE
+354ms ║Runtime (47852 bytes) successfully initialized in 249ms (v0.3.108.20180906) (351ms)
+356ms ║╔Execution stage started
+373ms ║║Comparison (enum) open changes_to (string) open = true (2ms)
+377ms ║║Cancelling condition #2’s schedules…
+379ms ║║Condition #2 evaluated true (12ms)
+394ms ║║Comparison (string) :1c43b70f8d5602b05bed1415aaf20be3: is_not_any_of (string) :cd3ff539c8748ad65874b6fd2275eb5e:,:60af85880bc093aae351d828afad0f56:,:59f060ae8446d0ec5a590a5ccb5fc8cb:,:f2c7dc34829ffa4568c261029f01706d:,:7e9c2bdc95d864979ef530aa29a57fdb: = true (9ms)
+397ms ║║Condition #10 evaluated true (16ms)
+399ms ║║Cancelling condition #1’s schedules…
+401ms ║║Condition group #1 evaluated true (state changed) (35ms)
+405ms ║║Cancelling statement #3’s schedules…
+465ms ║║Executed virtual command [Living].saveStateGlobally (50ms)
+473ms ║║Executed virtual command [Living].wait (1ms)
+475ms ║║Waiting for 1000ms
+2188ms ║║Executed physical command [Living].playTextAndResume([Open, 75]) (702ms)
+2189ms ║║Executed [Living].playTextAndResume (706ms)
+2194ms ║║Executed virtual command [Living].wait (1ms)
+2196ms ║║Requesting a wake up for Wed, Nov 14 2018 @ 5:12:55 PM PST (in 5.0s)
+2202ms ║╚Execution stage complete. (1846ms)
+2204ms ║Setting up scheduled job for Wed, Nov 14 2018 @ 5:12:55 PM PST (in 4.993s)
+2219ms ╚Event processed successfully (2218ms)
**