Has anyone contacted SmartThings support yet as recommended in this reply? Jarrett was planning to call during the week but if anyone has had time it would be great to learn more about what is going on here.
webCORE Dashboard Completely Broken. Please Help [UndeclaredThrowableException]
wjarrettc
#37
Phone support is not available on Sunday, they open at noon EDT / 9am PDT on Monday. I plan to call them Monday afternoon, work schedule allowing.
jasonrwise77
#39
Sorry, I was away this weekend, I do have some logs for you. This error I have seen before on another smartapp, and it was related to too many devices trying to be loaded. When I reduced the # of devices in that app the error went away. I am going to see if that possilby fixes it.
I am curious in my screen shot below it is showing smart app pause, what is actually being paused?

wjarrettc
#40
Support update: Called SmartThings support number on their website. Was connected to a tech fairly quickly after going through the automated menu routine. She quickly punted me over to SmartThings Classic support since I’m Hub v2 user on the classic app. Held there for about 20 minutes before putting in my phone number for a call back. Got a call back about 10 minutes later. Spent some time talking to the tech and then he escalated to his senior support tech. After about 10 more minutes on hold, they came back to me and said that they are seeing this issue which is the same as some other users had seen and it “was supposed to have been fixed already” and so they are escalating it to a higher level support team who will work on it now. He told me to expect to hear back later today hopefully on a fix. Fingers crossed.
wjarrettc
#41
I tried this for my Alexa issue and it absolutely fixed my problem. Around 135 devices is the maximum that I can have Alexa discover before it times out. The default setting for the Alexa Skill/SmartApp is to make all your devices and routines available. That breaks for me, but if I go in specify specific devices, I can get Alexa to work. Since I’m not really using motion and contact sensors to trigger routines in Alexa, this is a fine workaround for this problem.
I have a 2nd instance of WebCoRE that was created for my Presence Sensors back when the WC sensor needed to be installed in a separate instance. I can break the WebCore Dashboard on that second instance somewhere between 125-165 devices available, depending on server loading. It clearly seems to be a function of number of devices.
jasonrwise77
#42
I can confirm that by reducing my device count by 15 devices I can now get into my dashboard and pistons. Funny, now I have no live logging in the IDE, can’t ever win.
andyhawks
#43
Sorry @ipaterson that I also was not at home or by a desktop this weekend. Just catching up on this thread now.
I just tried eliminating devices as @jasonrwise77 mentioned just above and that totally worked for me - dashboard even loads on the machine I have been unable to get it to load on for the last couple weeks!
I am only putting one exclamation point on that sentence for now because I’ve experienced that it could load one day but not the next. But fingers crossed that we have a solution. Thanks very much @ipaterson @wjarrettc @jasonrwise77 for the team debugging and patience!
For reference, what’s working for me as of now:
- Down to 179 devices registered in webCORE from close to 300 when webCORE did not load
- Down to 1 webCORE instance instead of 2
- Memory usage of my instance decreased from 32% to 17%
- About 70 active pistons
- Every device registered in webCORE is referenced in a piston, no extraneous devices
- Removed all Hue Scenes loaded from Hue B Smart
- Removed motion sensors that were only being used in conjunction @bangali’s Rooms Manager app
- Removed all of my momentary switches created from the SmartThings UI, moved these to routines (note I did not have any routines when webCORE did not load, just webCORE pistons)
- Removed a few Smart Apps I wasn’t really using, here’s what I still have in place: ActionTiles, Alexa, Ask Alexa, Foscam Manager, GCal Search, Google, Hue B Smart, IFTTT, KuKu Harmony, Life360, Logitech Harmony, MyQ, NST Manager, Plex Manager, Ring, Rooms Manager, webCORE
So my ‘cleanup’ changed too many variables at once to isolate where the timeout may have happened, but hopefully this can help people who encounter this problem see an example of what didn’t work initially and what is working as of now (knock on wood).
IDE Live Logging is also wfm (works for me).
jasonrwise77
#44
@wjarrettc Just curious, are you having any issues viewing your live logging? Mine seems to hang and it started when my webcore issues started. My live logging does work, but it takes like 20 to 30 tries before it starts to flow.
Cannot login to https://dashboard.webcore.co/
elf
#45
Hmmm … last I heard there was something like a 300-device limit for querying in the ST database … dunno if this was ever changed.
andyhawks
#46
Even if a 300 device hard limit exists it appears you likely wouldn’t be able to hit it now before you reach that 20-second timeout. 60% of 300 seems to work ok.
ipaterson
#47
Glad to hear all of this, hopefully ST can resolve what now seems to clearly be a reduction in the number of devices are supported.
I only have about 30 physical devices so very far off from being able to test this. I guess I probably have about 50 but… so far behind in actually hooking stuff up.
Note to self and minions: if there is an error related to devices find out how many devices are involved.
wjarrettc
#48
I’m holding out hope that ST will fix the timeout, but short of that, I’m devising a backup plan to partition my devices between two instances and run them in parallel. Most of my pistons are room based (i.e., uses lights, motion, contact sensors, etc. only within a single room) so while this will be a pain, I think it will work.
Incidentally, is there a way to call a piston in one instance from another instance? I have some ideas of a workaround using Routines, but if I could call them directly that would be awesome.
ipaterson
#49
I believe that “superglobal” variables allow you to share state between instances but I’m not sure if they can be used as triggers. A superglobal is defined with two @ signs, e.g. @@command. There may be more info in the wiki.
jasonrwise77
#50
They must have drastically reduced the #, I have moved almost 100 devices into a new instance. That new instance is working and the old instance is still giving me errors. Is it at all possible that this 1 instance I have been using is somehow corrupt?
I am getting ready to move all my remaining devices into a new instance just to test my theory, lol.
ipaterson
#51
Oh, more conveniently you can use the web request URL for a piston to trigger it from another instance. That allows you to pass in arguments as GET parameters rather than trying to trigger off of superglobals.
jasonrwise77
#52
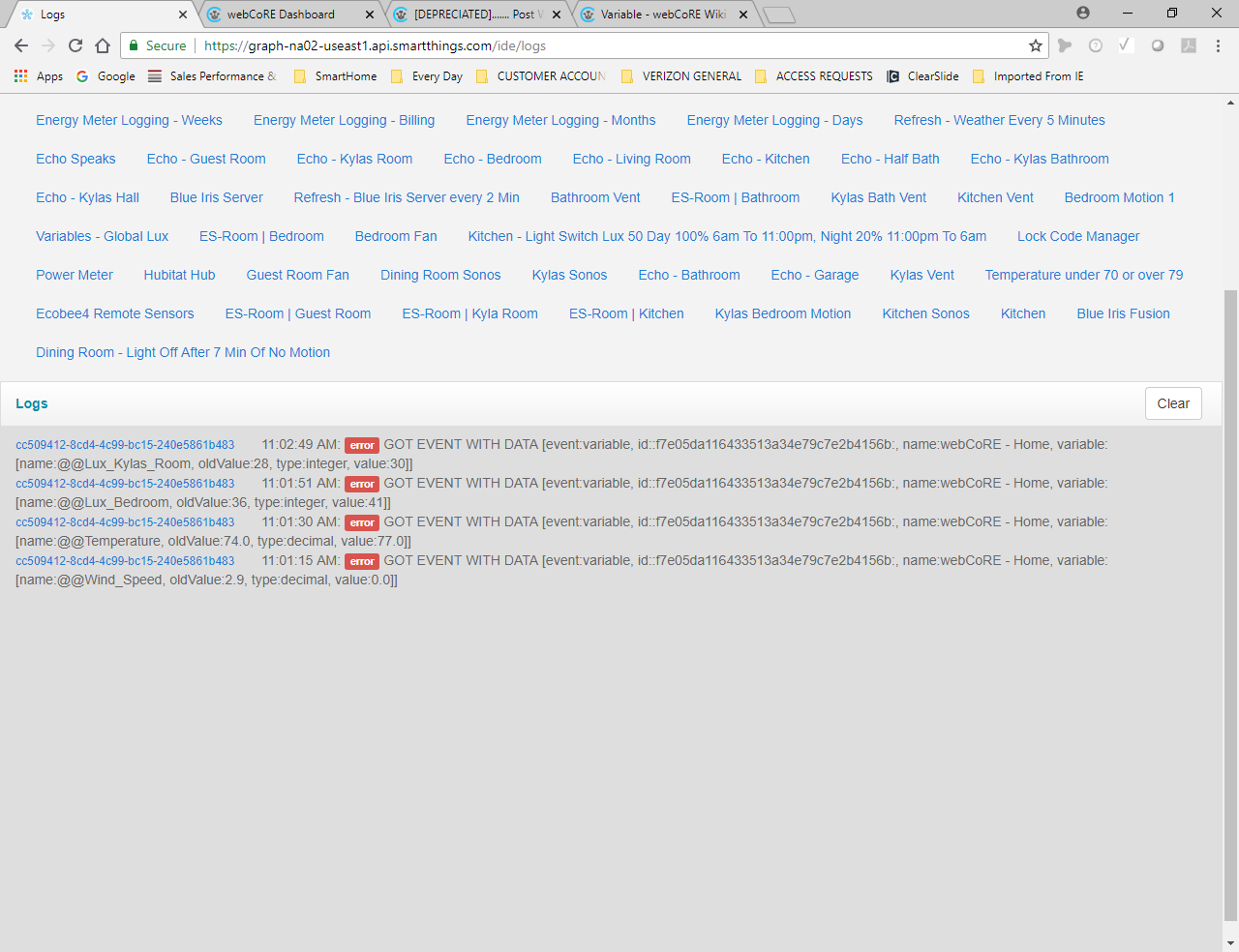
@ipaterson Hello, since I am using more than one instance now I am trying to use Super Global Variables, but am getting an error. All I did was add an extra @ onto each one and now I am getting an error. Any idea what I am doing wrong?
ipaterson
#53
Oops that is just leftover debug code from when Ady added the superglobals. Looks like an error, but not actually an error. I’ll remove it in the next release. Hopefully it works other than that!
If it is very annoying you can safely go to the webCoRE smart app code editor, search GOT EVENT and remove that line (line ~2104).
jasonrwise77
#54
I am still having timeout issues even on a new instance I just built, I am curious, should I be seeing this any time I open a piston from the dashboard? Reason I am asking is that only 1 out of 3 instances does it.
Dashboard: Request received to get piston :5bb67c61bee67949bf2b71483aad49b9:
wjwong54
#55
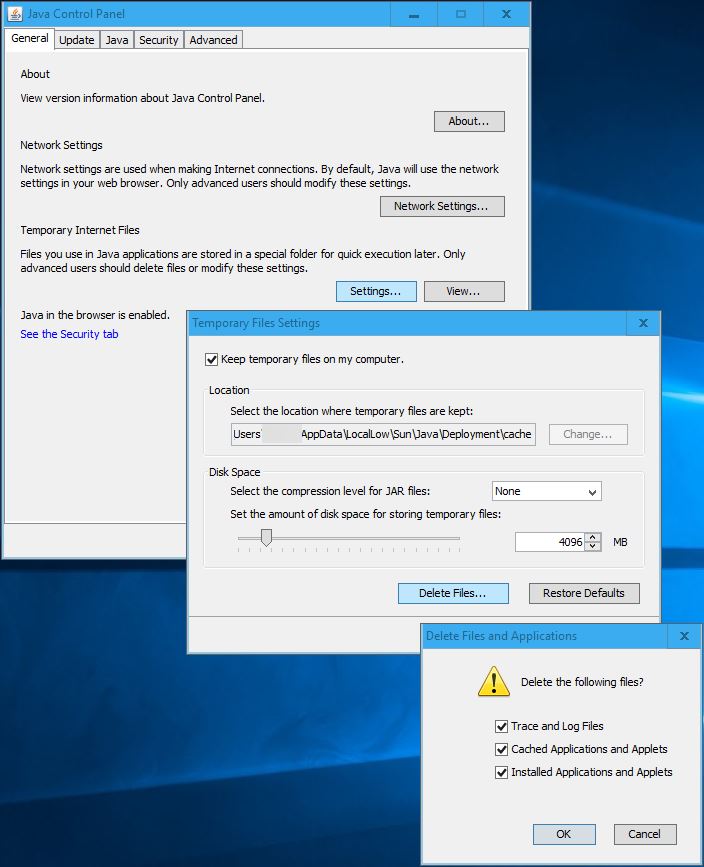
I am throwing out a possible solution since Java exceptions are being thrown - from experience, the Java temporary file store sometimes gets corrupted. So clearing it out may help some of the people on this thread.
To perform this action, launch the Java Control Panel, click on the “General” tab, click on “Settings…”, click on “Delete Files…”, check all boxes on the screen, click on “OK”.
The next time a Java application launches, it will load a fresh copy of code, if necessary.
I would also delete all temporary files in your browser’s cache.