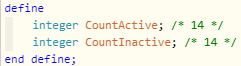I have been having the exact same problem as OP. The major difference for me is that I have no hub in my setup. All of my integrations are cloud-to-cloud. I can guarantee my hub is not bogged down because it doesn’t exist. 
It seems related to me. My system was working perfectly fine until that outage.
I have a few pistons that trigger on location mode change, and none of them missed an event until after the Dec 19 outage.
I also have a virtual device that has exactly one piston listening to its events, and I have seen that piston fail to fire frequently, even though ST’s log for that device shows the events.
Seems that way to me as well.
Does anybody have any ideas how to troubleshoot this?
Edit, in case this information helps:
I should add that ever since that outage, I’ve seen these exceptions in the live logs, and they seem to correlate with missed pistons:
8:12:17 AM: error org.springframework.jdbc.UncategorizedSQLException: Hibernate operation: could not execute query; uncategorized SQLException for SQL [select this_.id as id88_0_, this_.version as version88_0_, this_.date_created as date3_88_0_, this_.`key` as key4_88_0_, this_.type as type88_0_, this_.value as value88_0_ from server_config this_ where this_.`key`=?]; SQL state [null]; error code [0]; [SimpleAsyncTaskExecutor-626] Timeout: Pool empty. Unable to fetch a connection in 30 seconds, none available[size:50; busy:1; idle:0; lastwait:30000].; nested exception is org.apache.tomcat.jdbc.pool.PoolExhaustedException: [SimpleAsyncTaskExecutor-626] Timeout: Pool empty. Unable to fetch a connection in 30 seconds, none available[size:50; busy:1; idle:0; lastwait:30000]. @line 1149 (processSchedules)
That exception refers to line 1149 in the WebCore Piston SmartApp, which is:
runIn(t, timeHandler, [data: next])

ian_boje: